JMeter — Performance and Load Testing: Beginner’s Guide | Part II

After setting the basics in the previous article, we can now learn some more additional useful features of the JMeter. This article is going to cover the most used JMeter Config elements, Non-GUI execution of the test script and reporting.
JMeter Config Elements
These are elements that are executed before the sampler request at the same level. Configuration elements can be used to set up defaults and variables for later use by samplers. It should be noted that these elements are processed at the start of the scope in which they are found, i.e. before any samplers in the same scope. More details can be found in the documentation.

- HTTP Header Manager
The browser sends HTTP request header with some additional information to the server. This additional information is required to fulfil the server requirements to respond to that particular request. Each time the browser sends a request to a server attaching the headers with information like Accept-Language, Accept-Encoding, User-Agent, Referrer etc.

2. HTTP Cookie Manager
The cookie manager stores and sends cookies just like a web browser. If we have an HTTP Request and the response contains a cookie, the Cookie Manager automatically stores that cookie and will use it for all future requests to that particular website.
- When we enter the link https://the-internet.herokuapp.com/login in the browser, then one session cookie will be created.
- When we enter the valid credentials to log in, then the authentication will hit the request to login and the browser will store these cookies. But the JMeter won’t store the cookies like a browser. If we send our request without cookie manager, then we see something similar to below. That means it is expected to add a cookie manager.

- We can make the JMeter store the cookies by adding HTTP Cookie Manager.
- Right-click on the Thread Group and then select
Add-->Config Element-->HTTP Cookie Manager

If we compare the old request and the new request that is after adding the HTTP Cookie Manager, we can see that the cookies have been added to all the requests.
3. HTTP Cache Manager
As we know that JMeter has one config element which helps to mimic the browser behavior and make the test more realistic in terms of caching. ‘HTTP Cache Manager’ is used to simulate the browser caching behavior in JMeter by adding caching functionality to HTTP requests within its scope.
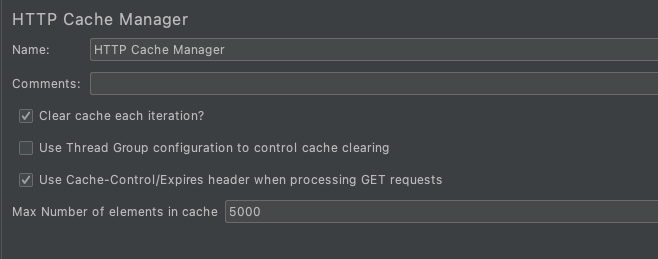
Clear cache each iteration?: If this option is selected, then the cache is cleared at the start of the thread.
Use Thread Group configuration to control cache clearing: This option provides the ability to configure whether a new iteration is with a new user or with the same user. It is mapped with the option ‘Same user on each iteration’ in the Thread group.
Use Cache Control/Expires header when processing GET requests: If this option is selected, then the Cache-Control/Expires value is checked against the current time. If the request is a GET request, and the timestamp is in the future, then the sampler returns immediately, without requesting the URL from the remote server. This is intended to emulate browser behavior.
Max Number of elements in cache: By default value is set to 5000 which indicates that the cache manager will store 5000 items in the cache. As much as you increase this value, the memory will be consumed more and JMeter may throw “out of memory” exception.
4. HTTP Request Defaults
We can set default values for HTTP Requests using JMeter HTTP request defaults in your software load test plan. Let’s say, we have a software load test plan with 10 HTTP requests and all requests are being sent to the same server. In this case, we can add HTTP request defaults JMeter and set server name in Server Name of HTTP request default in JMeter. Then we do not need to set Server Name in all 10 HTTP requests.
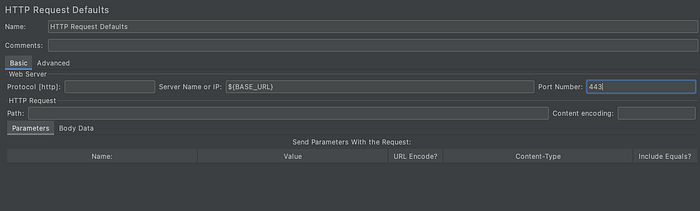
We can see below that there is no server name in any of the request. We just need to set the related path information. So server name will be inherited automatically from HTTP Request Defaults when we run the test.
5. HTTP Authorization Manager
When the web application requires the user to authenticate before launching the application, then we need to use Authorization manager. Without authentication, we could see the below message.
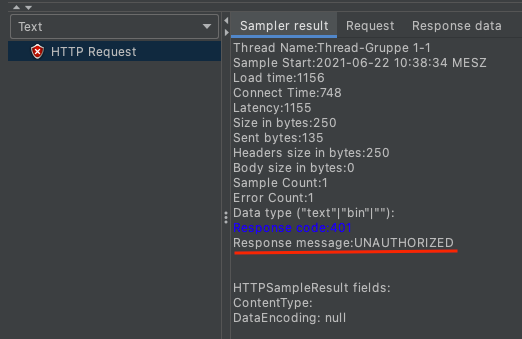
Now, we add Authentication Manager, and fill the necessary information.
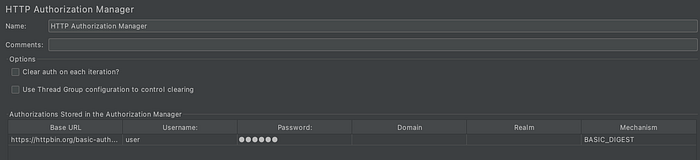
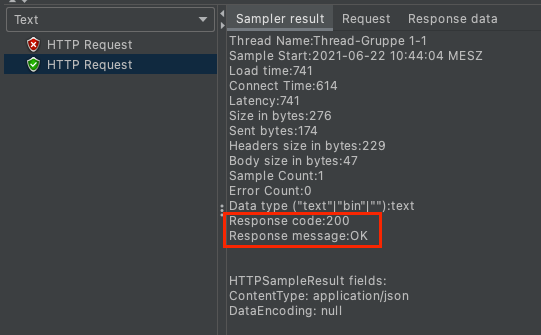
When we run the same test again with authentication manager.
If we have multiple users to execute the scenario, then we need to use CSV Data to set the values for each user, so that it can be implemented for all users.
Second way to handle authentication issue is to use Header Manager with the help of BeanShell Pre Processor. Even though it seems bit complex, we just need to provide Base64 encoded value. For that reason, we need to provide three lines of code inside Bean Shell Pre Processor.

Next step would be to define this auth variable inside our Header Manager, and run the test again by disabling the Authentication Manager.
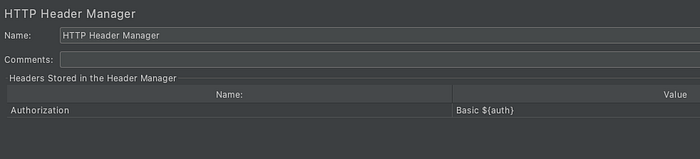
The output is the same.
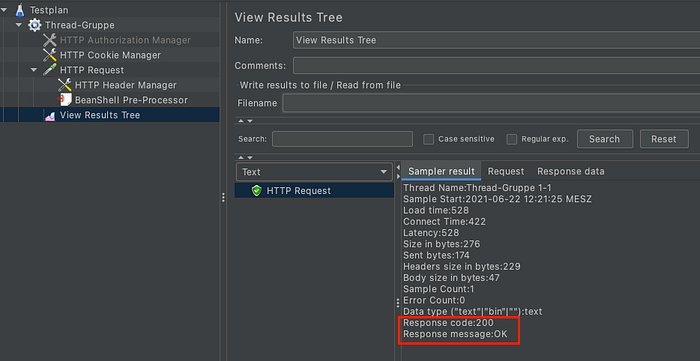
6. User Defined Variables
If any variable that needs to referred multiple times, then it would be better to save it in a variable, so that we can call it multiple times just by variable name.

After saving it in a variable, we can call it in our request. We can create as much variable as possible. Below we see our variable BASE_URL.
How to get data from CSV file
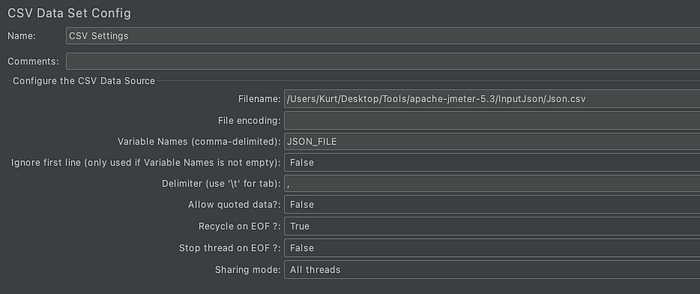
First, we should add CSV Data Set Config
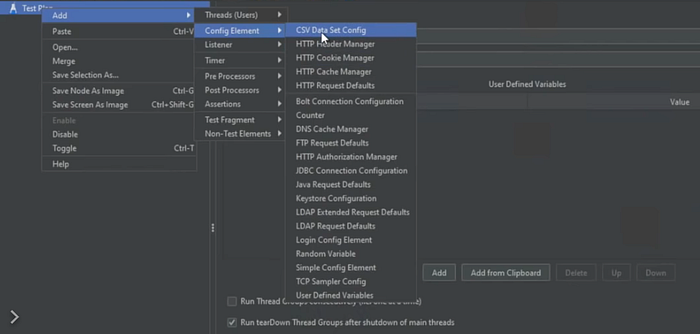
Second, we need to create one CSV file and add data inside.

File encoding section: we are leaving empty, unless we need to change encoding to something specific such as UTF-16, or US-ASCII — we can even create our own encoding by Edit option. This is only required if we need to use it in our CSV file. For instance, there might be some characters which requires changing encoding.
Variable Names: We can define our variables here, and we can refer values from CSV file using syntax $(variableName).
Ignore first line: If we want to ignore the first line in our CSV file, then we could make this option True.
Delimiter: We leave it as “,” as CSV default. However, we can change it if we use any other separators.
Allow quoted data: Should the CSV file allow values to be quoted? If enabled, then values can be enclosed in “ — double-quote — allowing values to contain a delimiter.
Recycle on EOF: If we don’t have enough users to execute our test, it recycles at the end of the file and start using the first data set again. If we make it true, then we should set Stop Thread on EOF as False to make sure that after executing the last data set, it should stop.
Sharing mode: If we have only one thread group, then it doesn’t make any sense to use it, but if we have more than one thread group, then we could choose all threads to share among them. Other options are current thread group — each file is opened once for each thread group in which the element appears, and current thread — each file is opened separately for each thread.
Now, it is time to execute one simple scenario to understand better.
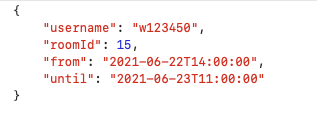
Scenario: This is a mobile application used for reserving a room. I will demonstrate 10 users, and each of them will make 10 reservation, which means 100 reservations totally. This will be executed within 10 seconds. They will first demonstrate booking a room (POST method), 10 seconds later they will try to view their reservation. Each user has a specific ID and have their own request bodies as a JSON file. They will reserve a different room with different time frames. Since each user has own ID and own request body we need to execute with the help of CSV Data Config.
I prepared 1 CSV file to save our users, and 10 JSON file to define JSON Body with the POST method.

And there will be 10 different JSON Body for each user. I saved them with the username in JSON format. (e.g. w123450.json)

I created two thread groups to separate the POST reservation with the GET reservation. They will complete booking action within 10 seconds, meanwhile I am checking also two other end points from the performance perspective.
We need to define the file location and the variable name if it is used.

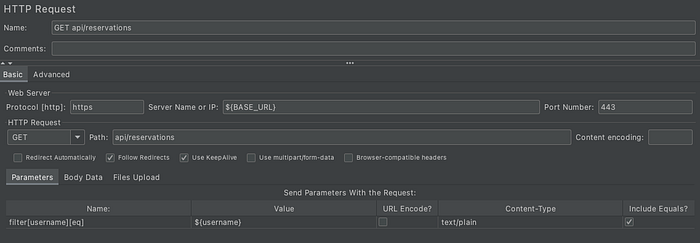
As we can see, if we had only one request body, then it would be enough to define our JSON body under Body Data. Since we have 10 different request bodies we need to read them from the external file.
For the second thread group, we need to provide another CSV Data as well.

Then, all we need to do it make it work with parameterization. “username” parameter will be read from the CSV file.
Executing Test Script Non-GUI Mode
- Once we finish the setup we need to save our work as jmx file. (e.g. workspaces.jmx).
- Open command line and change Dir to jmeter/bin
- Execute the command. (If you are on Windows, you don’t need to add sh command at the beginning.)

- -n → non gui mode
- -t → location of jmeter script
- -l → location of result file (It creates one CSV file automatically on the defined directory. I created one “CsvFiles” folder to save all created CSV files inside)
- -e → to create HTML report
- -o → location of output folder (we can create one folder to save our reports inside)
4. Analyze the HTML Report.
If we go to directory of HTML reports, we can see now our “index.html” file. The report, which is seen below, gives us every detail that we might need. Some examples will be provided below, which are related to response times, however detail information can be found on the website.

APDEX values are configurable. If we want to change the default values, we should go to our bin folder, where we installed JMeter. We need to open “user.properties” file with one of the text editor. Then we can change default APDEX values as desired.


As we see graphics are self explanatory — all we need to do is analyze.

We can also filter graphics just by clicking on the respective end point. If we just want to analyze our POST request for instance, we could deactivate others.


